
Audyt SEO jest procesem oceny i analizy strony internetowej pod kątem optymalizacji dla wyszukiwarek internetowych. Jego celem jest identyfikacja i usunięcie problemów, które mogą utrudniać lub uniemożliwiać indeksowanie i ranking strony przez wyszukiwarki.
Co zawiera audyt seo? Audyt SEO może zawierać analizę takich elementów, jak:
- struktura i treść strony,
- meta tagi i nagłówki,
- linkowanie wewnętrzne i zewnętrzne,
- szybkość ładowania strony,
- mobilność i dostępność,
- użycie słów kluczowych,
- błędy techniczne i inne problemy, które mogą wpływać na pozycję strony w wynikach wyszukiwania.
Audyt SEO można wykonać samodzielnie, ale może być też przeprowadzany przez specjalistów SEO. Aby przeprowadzić audyt SEO samodzielnie, należy skorzystać z dostępnych narzędzi SEO i wskazówek w nich zawartych. Możliwe narzędzia SEO do wykorzystania to:
- Google Search Console – bez tego narzędzia nawet nie ma co zaczynać audytu
- Screaming Frog, Sitebulb – narzędzia instalowane na komputerze do przeprowadzania audytów
- Ryte, Octopus Jet – narzędzia webowe, niestety dość drogie ponieważ skanowanie zależne jest od liczby podstron w serwisie
- Moz, Ahrefs, SEMrush, Senuto, Semstorm – narzędzia, które umożliwiają wykonanie audytu jako projektu
1. Czy można zrobić audyt SEO samemu?
Tak, ale potrzebna do tego jest odpowiednia wiedza i nierzadko doświadczenie. Aby wykonać audyt SEO samodzielnie, należy przejść następujące kroki:
- Przejrzyj swoją stronę internetową i zapisz listę problemów, które zauważyłeś. Przejrzyj także strony konkurencji aby spisać możliwe pomysły do realizacji pod kątem swojej strony.
- Użyj narzędzi do analizy SEO, takich jak Google Search Console, Screaming Frog, Sitebulb aby zbadać swoją stronę pod kątem takich elementów jak:
- szybkość ładowania strony,
- słowa kluczowe,
- linkowanie wewnętrzne,
- błędy techniczne SEO,
- użycie meta tagów i nagłówków,
- dostosowanie do urządzeń mobilnych i dostępność.
- Przeanalizuj swoje dane z narzędzi do analizy SEO, i znajdź problemy oraz potencjalne obszary do poprawy. Narzędzia typu Screaming Frog czy Sitebulb posiadają pełen manual i są w stanie podpowiedzieć co należy w serwisie poprawić i jak to wykonać.
- Zrób plan działania i rozwiązania dla problemów zidentyfikowanych w audycie.
- Przeprowadź wprowadzanie zmian i monitoruj wyniki. Najlepiej zastosuj monitorowaning słów kluczowych ale nie zapominaj także o indeksacji w GSC
- Pamiętaj, że SEO to proces ciągły, audyt powinien być powtarzany regularnie, aby upewnić się, że strona jest zoptymalizowana i dostosowana do aktualnych standardów i algorytmów wyszukiwarek. Z reguły taki audyt należy przeprowadzać co 6-9 miesięcy z uwzględnieniem aktualizacji algorytmów Google, które na przestrzeni danego czasu miały miejsce.
2. Historia domeny jako czynnik SEO
Historia domeny internetowej jest ważna w procesie pozycjonowania strony, ponieważ wyszukiwarki internetowe biorą pod uwagę różne czynniki przy ocenie jakości i autorytetu strony. Historia domeny może mieć wpływ na pozycję strony w wynikach wyszukiwania.
Sprawdzenie historii domeny pozwala na zrozumienie, jak strona była używana w przeszłości i czy była związana z jakimś spamem lub nieetycznymi praktykami SEO. W przypadku, gdy domena była już w przeszłości związana z takimi praktykami, może to negatywnie wpływać na pozycję strony w wynikach wyszukiwania.
Historia domeny może również pomóc w zrozumieniu linkowania strony, ponieważ pozwala to na zobaczenie, skąd pochodzą linki do strony i czy są one wartościowe. Linki pochodzące z wartościowych źródeł mogą pozytywnie wpływać na pozycję strony w wynikach wyszukiwania.
Historia domeny można sprawdzić za pomocą narzędzi takich jak Wayback Machine.
Adres serwisu: https://web.archive.org/
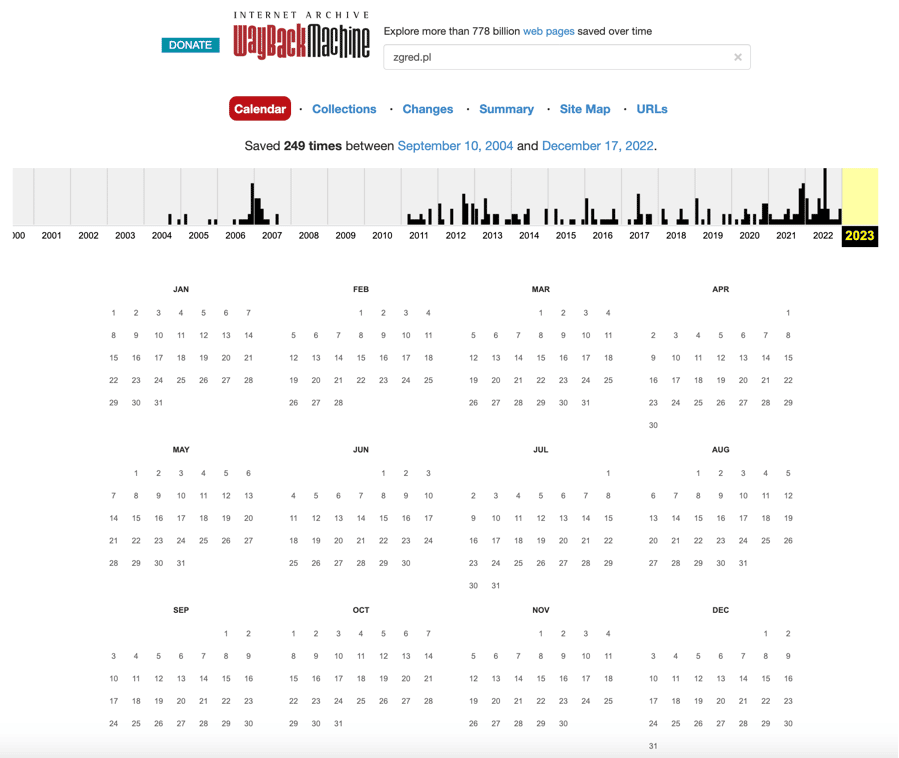
Kara ręczna od Google to decyzja, która może zostać podjęta przez pracowników Google, gdy strona jest związana z nieetycznymi praktykami SEO lub innymi problemami. Kara ręczna oznacza, że strona zostaje zdemaskowana z wyników wyszukiwania, co może mieć bardzo negatywny wpływ na ruch i przychody.
Jeśli strona przeszła karę ręczną w przeszłości, to może to mieć negatywny wpływ na pozycjonowanie strony, ponieważ Google może traktować ją jako „niepewną” i jest mniej skłonny do indeksowania jej i poprawnego rankowania w wynikach wyszukiwania. Dlatego też sprawdzenie historii domeny jest ważne, ponieważ pozwala to na zrozumienie, czy strona przeszła karę ręczną i czy może to mieć wpływ na obecne lub przyszłe pozycjonowanie.
Jeśli kupisz lub jakoś pozyskasz domenę z karą ręczną i taka informacja pojawi się w GSC de facto jesteś na straconej pozycji i należy pozyskać nową domenę i cały proces budowania marki i SEO zacząć od początku.
Migracja serwisu i historia domeny
Historia domeny pozwala także zweryfikować stare adresy URL. Jeżeli w przeszłości serwis był migrowany jeden lub nawet kilka razy i widzimy, że były drastyczne spadki widoczności w wynikach organicznych to narzędzie Way Back machine pozwala przynajmniej na częściowe odzyskanie starych adresów URL i wykonanie stosownych przekierowań 301. Taki zabieg pozwała w całości lub części odzyskać „moc SEO”, która była w przeszłości zbudowana.
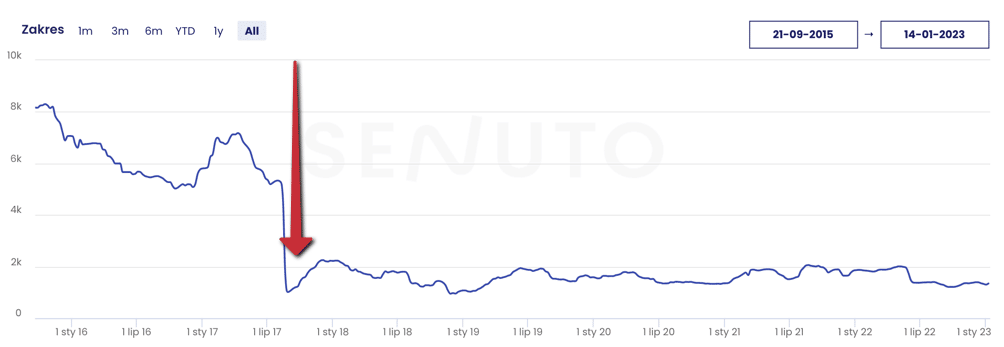
Ważne jest, aby prawidłowo przeprowadzić proces migracji strony www, aby uniknąć utraty ruchu organicznego i pozycji w wynikach wyszukiwania. W tym celu należy wykonać następujące kroki:
- Przygotuj mapowanie adresów URL: przed migracją należy przygotować mapowanie adresów URL, aby zapewnić, że wszystkie stare adresy URL będą przekierowywane na nowe adresy na nowej domenie.
- Ustaw przekierowanie 301: należy ustawić przekierowanie 301, aby zapewnić, że wszystkie linki zewnętrzne i wewnętrzne będą automatycznie przekierowywane na nowe adresy URL.
- Uaktualnij adresy URL w narzędziach analitycznych: należy uaktualnić adresy URL w narzędziach analitycznych, takich jak Google Analytics, aby móc nadal śledzić ruch na stronie.
- Zgłoś migrację do Google: należy zgłosić migrację do Google, aby przyspieszyć proces indeksowania nowych adresów URL.
- Monitoruj wyniki: po migracji należy monitorować wyniki, aby upewnić się, że strona nie traci pozycji i ruchu.
Jeśli migracja zostanie przeprowadzona prawidłowo, to wpływ historii domeny powinien być minimalny, jednakże jeśli proces migracji zostanie przeprowadzony nieprawidłowo, to może to negatywnie wpłynąć na pozycjonowanie strony.
3. Widoczność strony WWW w różnych narzędziach SEO
Sprawdzanie widoczności strony WWW pozwala na określenie, jak dobrze strona jest widoczna w wynikach wyszukiwania. To ważne, ponieważ im wyższa widoczność strony, tym więcej użytkowników będzie ją odwiedzać, aczkolwiek to kwestia sporna ponieważ tak zwany długi ogon (long tail) wcale nie musi generować dużego ruchu organicznego.
Duża widoczność w zakresie top50 czy top100 (zależnie od zastosowanego narzędzia) może świadczyć zarówno o dobrze wykonanej robocie ale również o tym, ze serwis jest widoczny na wiele słów kluczowych, które nie przyniosą żadnej korzyści sprzedażowej.
Istnieje wiele narzędzi SEO do badania widoczności, takich jak: Senuto, Semstorm, SEMrush, Ahrefs itp. Te narzędzia pozwalają na monitorowanie ruchu na stronie, pozycji w wynikach wyszukiwania oraz słów kluczowych, które przyciągają użytkowników.
Spadek widoczności strony WWW oznacza, że strona zajmuje niższą pozycję w wynikach wyszukiwania niż wcześniej. Może to być spowodowane przez wiele czynników, takich jak zmiana algorytmów wyszukiwarek, zmiana treści na stronie, konkurencja itp. Aby poprawić widoczność strony, należy przeanalizować przyczyny spadku i wprowadzić odpowiednie zmiany.
Wpływ algorytmów na widoczność serwisu
Aby weryfikować wpływ algorytmów Google na widoczność strony WWW, należy przeanalizować dane z narzędzi do monitorowania widoczności, takich jak Google Analytics i Google Search Console (do tych z reguły mamy dostęp i sa one bezpłatne) oraz z narzędzi zewnętrznych (płatnych) typu Senuto, Semstorm, Ahrefs, Semrush.
W Google Analytics można sprawdzić ruch na stronie, źródła ruchu oraz konwersje, co pozwala na określenie, czy zmiana widoczności strony ma wpływ na ilość odwiedzających oraz ich zachowanie na stronie.
Google Search Console pozwala na monitorowanie pozycji strony w wynikach wyszukiwania oraz słów kluczowych, które przyciągają użytkowników. Jeśli pozycja strony w wynikach wyszukiwania spada, należy sprawdzić, czy zmiana algorytmów Google jest przyczyną tego spadku – na przykład poprzez weryfikację ruchu per adres URL porównując wykresy sprzed i po wdrożeniu algorytmu Google.
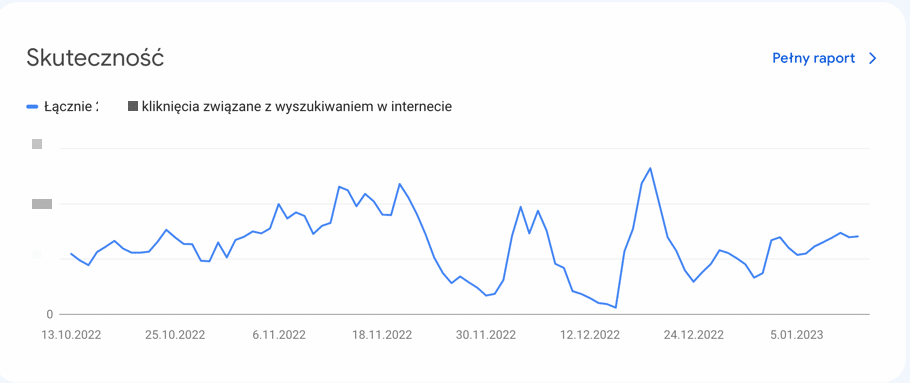
Spadek widoczności strony WWW może oznaczać, że algorytmy Google uznały stronę za mniej wartościową dla użytkowników. Może to być spowodowane przez wiele czynników, takich jak:
- zła jakość treści na stronie,
- brak odpowiednich meta tagów i opisów,
- brak linków zwrotnych do strony,
- nieodpowiednie dostosowanie strony do urządzeń mobilnych,
- konkurencja ze stronami o lepszej jakości,
- niewłaściwie strategia linkbuildingu poprzez np. oparcie jej na słowach kluczowych tz. money keywords
Aby poprawić widoczność strony, należy przeanalizować przyczyny spadku i wprowadzić odpowiednie zmiany. Z reguły wykonuje sie ukierunkowany audyt SEO np. audyt linków zwrotnych (najczęściej) oraz weryfikację technicznego SEO dla serwisu (np. GSC oraz linkowanie wewnętrzne), jak również architekturę.
Lista zmian w algorytmach Google znajduje się pod adresami:
- https://developers.google.com/search/updates/ranking – oficjalny spis od Google
- https://www.searchenginejournal.com/google-algorithm-history/
- https://moz.com/google-algorithm-change
Spam Core Update
Algorytm Google typu „Spam Core Update” jest częścią systemu oceny jakości stron internetowych przez wyszukiwarkę Google. Jego celem jest identyfikacja i odrzucanie stron, które stosują nieetyczne praktyki pozycjonowania, takie jak spamowanie wyszukiwarek, kupowanie linków, tworzenie treści sztucznie generowanych itp.
W przypadku aktualizacji Spam Core, algorytm Google analizuje strony pod kątem takich czynników, jak:
- jakość treści,
- słowa kluczowe,
- linki zwrotne,
- historia domeny,
- nieetyczne praktyki pozycjonowania.
Jeśli algorytm Google stwierdzi, że strona stosuje nieetyczne praktyki pozycjonowania, może ją obniżyć w wynikach wyszukiwania lub całkowicie wykluczyć z wyników wyszukiwania. W Polsce najczęściej problem dotyczy linków zwrotnych (strategii linkbuildingu) oraz nadmiernego korzystania ze słów kluczowych.
Co ciekawe Google mówi, że samodzielnie potrafi odciąć wpływ linków na pozycje (zgodne z poniższym cytatem) ale jakoś nikt mu nie wierzy 😉
W przypadku aktualizacji dotyczącej spamerskich linków (aktualizacji, która dotyczy spamu z linkami), wprowadzenie zmian może nie przynieść poprawy. Dzieje się tak, ponieważ usunięcie przez nasze systemy wpływu linków spamerskich może spowodować, że witryna utraci swoją pozycję w rankingu, jaka została wygenerowana dzięki tym linkom. Nie będzie można odzyskać żadnych potencjalnych korzyści dla pozycji w rankingu wygenerowanych przez te linki.
Helpful Content Update
Algorytm Google „Helpful Content Update” jest jednym z wielu algorytmów, które Google stosuje do oceny jakości treści na stronie internetowej. Jego celem jest wyłonienie najlepszych stron, które są najbardziej pomocne dla użytkowników, oraz zwiększenie ich widoczności w wynikach wyszukiwania.
Algorytm ten skupia się na zawartości strony, szczególnie na jej jakości i przydatności dla użytkowników. Google analizuje różne elementy treści, takie jak: długość tekstu, ilość słów kluczowych, unikalność treści, a także czy treść jest aktualna i odpowiada na pytanie użytkownika.
Google bierze również pod uwagę interakcje użytkowników z treścią, takie jak czas spędzony na stronie, liczba wyświetleń, liczba kliknięć, a także liczba i jakość linków prowadzących do strony.
Algorytm „Helpful Content Update” ma na celu poprawienie jakości treści w wynikach wyszukiwania, co przynosi korzyści zarówno dla użytkowników, jak i dla właścicieli stron, które znajdują się wysoko w wynikach wyszukiwania.
Więcej na temat Helpful Content Update pod adresem: https://developers.google.com/search/blog/2022/08/helpful-content-update
Product Review Update
Algorytm Google „Product Review Update” jest jednym z aktualizacji algorytmów Google, które mają na celu poprawienie jakości wyników wyszukiwania dla zapytań związanych z opiniami produktów.
Ten algorytm jest skierowany do stron internetowych, które zawierają opinie na temat produktów, takich jak sklepy internetowe, fora dyskusyjne czy blogi.
Algorytm ten działa poprzez weryfikację jakości opinii na stronach, które te opinie zawierają. Oceniana jest m.in. ich autentyczność, rzetelność i różnorodność. Strony z opiniami, które spełniają określone kryteria, mogą być lepiej widoczne w wynikach wyszukiwania.
W efekcie tego algorytmu strony, które oferują autentyczne, rzetelne i różnorodne opinie na temat produktów, są lepiej widoczne w wynikach wyszukiwania, a tym samym mogą przyciągać więcej ruchu. Z kolei strony, które oferują opinie niskiej jakości lub sfałszowane opinie mogą zostać obniżone w rankingach wyników wyszukiwania.
Widoczność strony www teraz i w przeszłości, na co zwrócić uwagę?
Widoczność strony WWW jest wynikiem wielu czynników, które mogą się zmieniać zarówno w przeszłości, jak i obecnie. W przeszłości, widoczność strony była często uzależniona od ilości linków zwrotnych do strony, co było ważnym czynnikiem w algorytmach wyszukiwarek. Obecnie, jakość treści, użyteczność strony, dostosowanie do urządzeń mobilnych i wiele innych czynników również mają znaczenie dla widoczności strony.
Aby zwiększyć widoczność strony WWW, należy zwrócić uwagę na następujące czynniki:
- Jakość treści: Treści na stronie powinny być unikalne, aktualne i interesujące dla użytkowników. Warto pamiętać, że algorytmy Google premiują strony z wysokiej jakości treścią, takie jak artykuły eksperckie i dłuższe formy treści. Przy aktualizacjach HelpfulContent Update warto sprawdzić czy serwis posiada strony ze zduplikowaną treścią, podstrony gdzie tej treści jest mało lub wcale itp, treść skopiowana, treść lekko przeedytowana itp.
- Słowa kluczowe: Słowa kluczowe powinny być odpowiednio wykorzystywane w treściach, meta tagach, opisach i nagłówkach, aby pomóc wyszukiwarkom zrozumieć tematykę strony. Najczęściej dotyczy to upychania słów kluczowych oraz kanibalizacji.
- Linki zwrotne: Linki zwrotne do strony pochodzące z innych, wysokiej jakości stron pozytywnie wpływają na pozycję strony w wynikach wyszukiwania. To jest praktycznie nagminny i najczęstszy problem w Polsce.
- Dostosowanie do urządzeń mobilnych: Coraz więcej użytkowników korzysta z internetu na urządzeniach mobilnych, dlatego ważne jest, aby strona była dostosowana do tych urządzeń. Nigdy nie spotkaliśmy tego typu problemu aczkolwiek Google twierdzi, że strony „niemobilne” mogą gorzej rankować.
- Szybkość ładowania: Szybkość ładowania strony jest ważnym czynnikiem, ponieważ użytkownicy nie chcą czekać długo na załadowanie się strony. Wpływ może mieć np. hosting, skrypt itd.
- Bezpieczeństwo: Strona powinna być bezpieczna dla użytkowników, dlatego ważne jest, aby korzystać z certyfikatów SSL i prawidłowo konfigurować protokół HTTPS.
- Optymalizacja dla wyszukiwarek: Optymalizacja dla wyszukiwarek (SEO) polega na stosowaniu odpowiednich metod i technik, które pomagają wyszukiwarkom zrozumieć zawartość strony i ułatwiają jej indeksowanie. W tym przypadku sugerujemy wykorzystywać fragmenty rozszerzone.
Warto pamiętać, że algorytmy wyszukiwarek stale się zmieniają, dlatego ważne jest ciągłe monitorowanie i dostosowywanie działań do aktualnych wytycznych. Wszelkie duże spadki czy wzrosty widoczności należy weryfikować pod kątem ewentualnych algorytmów, spadków, zmian w serwisie.
4. Analiza słów kluczowych
Analiza słów kluczowych polega na określeniu fraz, które są ważne dla danej branży lub tematu, a które użytkownicy wprowadzają w wyszukiwarkach. Przygotowanie słów kluczowych i serwisu do pozycjonowania polega na dostosowaniu treści serwisu oraz meta tagów do tych słów kluczowych. Aby przeanalizować słowa kluczowe, można skorzystać z narzędzi SEO do analizy słów kluczowych, takich jak Google Keyword Planner lub Senuto, Semstorm czy Semrush oraz Ahrefs. Następnie przypisujemy słowa kluczowe do stron docelowych, czyli do poszczególnych podstron serwisu, które odpowiadają konkretnemu słowu kluczowemu. Jeśli chodzi o grę, to w przypadku gdy nie mamy strony docelowej dla danego słowa kluczowego, możemy stworzyć nową podstronę, która będzie odpowiadać temu słowu kluczowemu.
W przypadku, gdy nie mamy strony docelowej dla danego słowa kluczowego, możemy również stworzyć landing page, czyli stronę przygotowaną specjalnie dla danego słowa kluczowego. Landing page powinna zawierać treści odpowiadające słowu kluczowemu, ale także powinna być przyjazna dla użytkownika i zachęcać do dalszej interakcji z serwisem.
Kolejnym krokiem jest optymalizacja serwisu pod kątem wybranych słów kluczowych. Oznacza to dostosowanie meta tagów, nagłówków, treści, linkowanie wewnętrzne i zewnętrzne do wybranych fraz. Ważne jest również, aby zadbać o jakość treści na stronie oraz o jakość linków przychodzących do serwisu.
Na końcu warto regularnie monitorować pozycję serwisu w wynikach wyszukiwania dla wybranych słów kluczowych, aby móc ewentualnie wprowadzić korekty i poprawiać pozycję.
Jak podzielić słowa kluczowe w procesie pozycjonowania strony
Podział słów kluczowych w procesie pozycjonowania strony jest ważny, aby skutecznie dostosować treści serwisu do potrzeb użytkowników oraz aby skutecznie monitorować i optymalizować pozycję serwisu w wynikach wyszukiwania.
Jednym z popularnych sposobów podziału słów kluczowych jest podział na słowa kluczowe ogólne i słowa kluczowe długiego ogona. Słowa kluczowe ogólne to frazy składające się z kilku słów, które są często wprowadzane przez użytkowników w wyszukiwarkach, np. „pozycjonowanie stron internetowych„. Słowa kluczowe długiego ogona to frazy składające się z więcej niż kilku słów, które są rzadziej wprowadzane przez użytkowników, ale które są bardziej precyzyjne i dokładnie odpowiadają potrzebom użytkownika, np. „pozycjonowanie stron internetowych dla małych firm”.
Inny sposób podziału słów kluczowych to podział na słowa kluczowe kompetencyjne i transakcyjne. Słowa kluczowe kompetencyjne to frazy, które odpowiadają potrzebie informacyjnej użytkownika, np. „jak pozycjonować stronę internetową?”. Słowa kluczowe transakcyjne to frazy, które odpowiadają potrzebie realizacji transakcji przez użytkownika, np. „pozycjonowanie stron internetowych cennik”.
Warto pamiętać, że podział słów kluczowych powinien być dostosowany do specyfiki danej branży i tematyki serwisu, a także do analizy słów kluczowych i potrzeb użytkowników.
Punkty, na które warto zwrócić uwagę podczas opracowywania listy słów kluczowych dla e-commerce lub stron usługowych:
- określenie branży i kategorii produktów oraz oferty produktowej – one będą bazą wyjściową dla fraz kluczowych, które będą strategiczne dla serwisu,
- weryfikacja średniej liczby wyszukań dla danej frazy,
- określenie trudności frazy – trudność określa tutaj konkurencja w zależności od tego, co znajduje się w top 10 stron na zapytanie,
- sezonowość frazy – istotne jest wybadanie, jak rozkłada się średnia miesięczna liczba wyszukań w ciągu roku. Najlepszym scenariuszem jest pozycjonowanie na frazy, które mają taką samą ilość zapytań przez cały rok. Dzięki temu ruch na stronie i zarazem sprzedaż może być stabilniejsza. W przypadku fraz sezonowych, jak np. „znicze” czy „bombki”, duży wolumen będzie tylko raz do roku. To naturalnie przełoży się na sprzedaż w okresie wzmożonego ruchu na stronie,
- frazy pokrewne i synonimy – przy dobieraniu fraz warto również poszukać synonimów oraz wyrażeń pokrewnych, które będą mogły kierować wraz z frazą główną na podstronę.
Słowa kluczowe ze względu na intencję użytkownika
W audycie SEO, słowa kluczowe mogą być podzielone ze względu na intencję użytkownika, co pozwala na lepsze zrozumienie potrzeb użytkowników i skuteczniejsze dostosowanie treści serwisu do ich potrzeb.
Najczęściej wyróżnia się następujące intencje użytkowników:
- Intencja informacyjna – użytkownik szuka informacji na dany temat, np. „jak pozycjonować stronę internetową?”
- Intencja transakcyjna – użytkownik szuka sposobu na realizację transakcji, np. „pozycjonowanie stron internetowych cennik”
- Intencja nawigacyjna – użytkownik szuka określonej strony internetowej, np. „pozycjonowanie stron internetowych”
- Intencja zorientowana na lokalizację – użytkownik szuka informacji na temat dostępności produktów lub usług w określonej lokalizacji, np. „pozycjonowanie stron internetowych Warszawa”
- Intencja zorientowana na markę – użytkownik szuka informacji na temat określonej marki, np. „pozycjonowanie stron internetowych Semgence”
Warto pamiętać, że użytkownicy często posiadają mieszaną intencję, np. chcą znaleźć informacje na temat pozycjonowania stron internetowych w danej lokalizacji. Dlatego ważne jest, aby analizować intencję użytkowników na podstawie różnych słów kluczowych i dostosowywać treści serwisu do różnych intencji.
Google analizuje intencję użytkownika na podstawie różnych czynników, takich jak:
- Słowa kluczowe wprowadzone przez użytkownika do wyszukiwarki
- Kontekst wprowadzonych słów kluczowych
- Historia wyszukiwania użytkownika
- Lokalizacja geograficzna użytkownika
- Urządzenie, z którego korzysta użytkownik
Google używa tych informacji, aby określić intencję użytkownika i udostępnić mu najbardziej trafne i przydatne wyniki wyszukiwania. Przykładowo, jeśli użytkownik wprowadzi frazę „pozycjonowanie stron internetowych”, Google może zakładać, że ma on intencję informacyjną i udostępni mu wyniki związane z tym tematem, np. artykuły na temat pozycjonowania stron internetowych, filmy instruktażowe itp. Natomiast jeśli użytkownik wprowadzi frazę „pozycjonowanie stron internetowych cennik” Google będzie rozumiał, że użytkownik poszukuje cenników ofert pozycjonowania stron.
Google również używa swoich algorytmów, takich jak BERT, aby zrozumieć znaczenie wprowadzonych słów kluczowych i kontekstu, co pozwala na jeszcze lepsze dopasowanie wyników wyszukiwania do intencji użytkownika.
5. Analiza wpływu algorytmów Google na pozycjonowany serwis
Wyżej wymieniłem kilka algorytmów Google. W audycie, jeśli dotyczy to już pozycjonowanego serwisu, powinna znaleźć się analiza wpływu algorytmów na serwis – no chyba, że nic się nie wydarzyło, wtedy ten punkt można pominąć.
Analiza wpływu algorytmów Google na pozycjonowany serwis jest ważnym elementem audytu SEO, ponieważ pozwala na zrozumienie, jak algorytmy Google wpływają na pozycję serwisu w wynikach wyszukiwania. Jeżeli widzimy spadki na widoczności to analizujemy okres od momentu spadku plus i minus 2-3 tygodnie – czyli tak naprawdę ok 6 tygodniowy odcinek czasu. Jednocześnie nie podejmujemy pochopnych decyzji w trakcie trwania aktualizacji tylko cierpliwie czekamy, aż ten pier**nik się skończy.
Przy analizie algorytmów, warto zwrócić uwagę na następujące czynniki:
- Jakość treści na serwisie – algorytmy Google premiują treści wysokiej jakości, które są unikalne, odpowiednie i przydatne dla użytkowników.
- Techniczne SEO – algorytmy Google premiują serwisy, które są zoptymalizowane pod kątem SEO, takie jak prawidłowe meta tagi, nagłówki, linkowanie wewnętrzne i zewnętrzne.
- Mobilne strony – algorytmy Google premiują serwisy, które są przystosowane do wyświetlania na urządzeniach mobilnych.
- Szybkość serwisu – algorytmy Google premiują serwisy, które ładują się szybko i sprawnie działają.
- Linki zewnętrzne – algorytmy Google premiują serwisy, które posiadają dobrze zbudowane odnośniki do serwisu (czyli tak zwane White HAT SEO), ale to rzadkość w Polsce więc tutaj jest dużo do nadrobienia.
Aby analizować algorytmy Google, można skorzystać z narzędzi do analizy SEO, takich jak Google Search Console, SEMrush, Ahrefs itp. Niestety polskie narzędzia SEO nie mają bazy odnośników więc jw trakcie analizy jesteśmy skazani na płatne, zagraniczne narzędzia.

Ważne jest również, aby stale testować różne działania i strategie pozycjonowania, aby zrozumieć, co działa najlepiej dla naszego serwisu. Może to obejmować testowanie różnych słów kluczowych, optymalizacji treści, linkowania, strategii reklamowych itp.
Analizując algorytmy Google, warto również pamiętać, że algorytmy są stale ulepszane i zmieniane przez Google, dlatego ważne jest, aby stale śledzić i analizować zmiany w algorytmach, aby móc dostosować swoje działania pozycjonowania do aktualnych wytycznych i trendów.
6. Analiza konkurencji w wynikach organicznych
Od razu podkreślam, że konkurencji biznesowa nie musi być taka sama jak organiczna. W wielu przypadkach, szczególnie przy sklepach internetowych, konkurencja organiczna jest dużo większa niż wydaje się właścicielowi biznesu.
Analiza konkurencji w wynikach organicznych pozwala na zrozumienie, jakie działania przynoszą sukces w danej branży oraz jakie działania mogą być skuteczne dla naszego serwisu.
Aby skutecznie analizować konkurencję w wynikach organicznych, można skorzystać z następujących metod:
- Analiza słów kluczowych – analiza, jakie słowa kluczowe są używane przez konkurencję, pozwala na zrozumienie, jakie treści i tematy są dla nich ważne i jakie słowa kluczowe mogą być skuteczne dla naszego serwisu.
- Analiza treści – analiza treści konkurencji pozwala na zrozumienie, jakie treści są skuteczne w danej branży oraz jakie są ich mocne i słabe strony, co pozwala na dostosowanie treści serwisu do tych trendów i na podjęcie działań, które pozwolą na przewyższenie konkurencji.
- Analiza linków – analiza linków przychodzących do stron konkurencji pozwala na zrozumienie, jakie serwisy i strony linkują do nich oraz jakie strategie linkowania stosują. To pozwala na zwiększenie autorytetu serwisu poprzez pozyskiwanie linków z podobnych źródeł.
- Analiza działań reklamowych – analiza działań reklamowych konkurencji pozwala na zrozumienie, jakie reklamy i kampanie reklamowe są skuteczne w danej branży oraz na podjęcie działań, które pozwolą na przewyższenie konkurencji.
- Analiza social media – analiza działań na social media pozwala na zrozumienie, jakie treści są skuteczne w danej branży oraz jakie strategie komunikacji są stosowane przez konkurencję.
Ważne jest, aby analizować konkurencję regularnie i stale monitorować zmiany w ich działaniach, aby móc dostosować swoje działania pozycjonowania do aktualnych trendów i wytycznych.
Analiza słów kluczowych konkurencji pozwala na zrozumienie, jakie słowa kluczowe są używane przez konkurencję oraz jakie treści i tematy są dla nich ważne.
- Analiza menu – wykorzystanie narzędzi SEO, takich jak SEMrush, Ahrefs czy Moz, pozwala na analizę menu konkurencji, czyli jakie słowa kluczowe są używane w nagłówkach, tytułach stron, meta tagach itp.
- Analiza bloga – przejrzenie bloga konkurencji pozwala na zrozumienie, jakie treści są publikowane, jakie słowa kluczowe są używane oraz jakie są popularne tematy.
- Analiza treści – analiza treści konkurencji pozwala na zrozumienie, jakie treści są skuteczne w danej branży oraz jakie są ich mocne i słabe strony, co pozwala na dostosowanie treści serwisu do tych trendów i na podjęcie działań, które pozwolą na przewyższenie konkurencji.
Analizując słowa kluczowe konkurencji, warto pamiętać, że nie należy naśladować ich dokładnie, ale skupić się na zrozumieniu jakie słowa kluczowe są dla nich ważne i jakie treści publikują, a następnie dostosować swoje działania pozycjonowania do aktualnych trendów i wytycznych.
Struktura serwisu konkurencji
Analiza struktury serwisu konkurencji pozwala na zrozumienie, jakie treści i słowa kluczowe są ważne dla konkurencji oraz jakie działania pozycjonowania stosują. Może to pomóc w znalezieniu słów kluczowych, których nie ma na analizowanej stronie.
- Analiza nagłówków i tytułów stron – przejrzenie nagłówków i tytułów stron konkurencji pozwala na zrozumienie, jakie słowa kluczowe są używane w nagłówkach i tytułach oraz jakie treści są ważne dla konkurencji.
- Analiza meta tagów – analiza meta tagów konkurencji pozwala na zrozumienie, jakie słowa kluczowe są używane w opisach stron oraz jakie treści są ważne dla konkurencji.
- Analiza linków wewnętrznych – przejrzenie linków wewnętrznych konkurencji pozwala na zrozumienie, jakie treści są ważne dla konkurencji oraz jakie słowa kluczowe są używane w linkach.
- Analiza treści – analiza treści konkurencji pozwala na zrozumienie, jakie treści są skuteczne w danej branży oraz jakie słowa kluczowe są używane.
Analizując strukturę serwisu konkurencji, należy pamiętać o wyciągnięciu wniosków i wykorzystaniu tych informacji do poprawy struktury swojego serwisu oraz pozycjonowanie swojego serwisu. Zawsze analizuj menu główne oraz stopkę serwisu – niejednokrotnie w stopce znajdziesz wiele ciekawych rzeczy pod kątem SEO.
Linki zewnętrzne konkurencji
Analiza linkowania zewnętrznego konkurencji pozwala na zrozumienie, jakie serwisy i strony linkują do nich oraz jakie strategie linkowania stosują. Może to pomóc w znalezieniu nowych możliwości pozyskiwania linków dla swojego serwisu. Możemy analizować dl aprzykładu:
- Analiza typów linków – analiza typów linków przychodzących do konkurencji pozwala na zrozumienie, jakie rodzaje linków są dla nich ważne i jakie strategie linkowania stosują.
- Analiza anchorów – analiza anchorów linków przychodzących do konkurencji pozwala na zrozumienie, jakie słowa kluczowe i frazy są używane w anchorach oraz jakie treści są ważne dla konkurencji.
- Analiza profilu linków – analiza profilu linków przychodzących do konkurencji pozwala na zrozumienie, jakie serwisy i strony linkują do konkurencji oraz jakie rodzaje serwisów są ważne dla ich pozycji.
Analizując linkowanie zewnętrzne konkurencji, należy pamiętać o wyciągnięciu wniosków i wykorzystaniu tych informacji do poprawy własnej strategii linkowania oraz pozycjonowania swojego serwisu. Można to robić przez pozyskiwanie linków z podobnych źródeł, używając podobnych słów kluczowych w anchorach czy koncentrując się na pozyskiwaniu linków z podobnych typów serwisów.
Uwaga: ślepe powielanie pozycjonowania tak jak robi to konkurencja może się skończyć źle bo w międzyczasie weszły do użycia algorytmy Google np. spambrain. Tym samym jeśli ktos nagminnie stosuje marketing szeptany w postaci syfiastych for to lepiej tego unikać bo niekoniecznie się to obecnie sprawdzi – po prostu konkurencja ma tyle duży i bogaty profil linków, że ten śmietnik mu nie przeszkadza w prawidłowym rankowaniu.
7. Budowa struktury serwisu pozycjonowanego
Struktura czy tez architektura pozycjonowanego serwisu jest bardzo ważnym czynnikiem w procesie pozycjonowania. Istotnymi elementami w kwestii hierarchii witryny są:
- struktura adresów URL,
- rozbicie na kategorie,
- nawigacja z menu głównego,
- nawigacja ze strony głównej,
- łatwość korzystania z elementów menu nawigacyjnego,
- linkowanie wewnętrzne,
- stworzenie mapy witryny dla użytkownika i dla wyszukiwarek,
- logiczna hierarchia linkowania wewnętrznego na stronie.
Więcej na temat architektury przeczytasz tutaj: https://developers.google.com/search/docs/fundamentals/seo-starter-guide#hierarchy
Kategorie w serwisie
Dobra struktura kategorii serwisu internetowego powinna być prosta, logiczna i przejrzysta dla użytkownika. Oto kilka wskazówek dotyczących dobrej struktury kategorii serwisu internetowego:
- Kategorie powinny być odpowiednio zagregowane – powinny odpowiadać naturalnym kategoriom treści na stronie, takie jak produkty, usługi, artykuły czy blogi.
- Kategorie powinny być zwięzłe i precyzyjne – powinny być opisane jasno i jednoznacznie, aby użytkownik mógł łatwo zrozumieć, czego może się spodziewać po wejściu na daną stronę.
- Kategorie powinny być przejrzyste – powinny być łatwo dostępne dla użytkownika, dzięki czemu będzie mógł szybko i łatwo znaleźć potrzebne mu treści.
- Kategorie powinny być zoptymalizowane pod kątem SEO – powinny zawierać odpowiednie słowa kluczowe i być zoptymalizowane pod kątem pozycjonowania, aby ułatwić ich indeksowanie przez wyszukiwarki.
- Kategorie powinny być elastyczne – powinny pozwalać na dodawanie i usuwanie podkategorii, jeśli zajdzie taka potrzeba.
- Kategorie powinny być zgodne z UX – powinny być zgodne z dobrymi praktykami projektowania interfejsu użytkownika, takie jak przejrzystość, łatwość nawigacji i przewidywalność.
Dobra struktura kategorii pozwala na lepszą nawigację po serwisie przez użytkowników, a także ułatwia indeksowanie przez wyszukiwarki. Dzięki temu, użytkownicy szybciej znajdą potrzebne im informacje, a serwis będzie lepiej widoczny w wynikach wyszukiwania.
Menu w serwisie
Dobra struktura menu serwisu internetowego powinna być prosta, czytelna i intuicyjna. Oto kilka wskazówek dotyczących dobrej struktury menu serwisu internetowego:
- Prosta i czytelna – menu powinno być łatwe do zrozumienia i przeglądania, a jego struktura powinna być prosta i przejrzysta.
- Hierarchiczna – struktura menu powinna być hierarchiczna, co oznacza, że powinno zawierać główne pozycje oraz podpozycje, które służą do przeglądania konkretnych sekcji serwisu.
- Intuicyjna – menu powinno być zorganizowane w sposób, który pozwala użytkownikom łatwo znaleźć to, czego szukają, bez konieczności przeszukiwania całego serwisu.
- Aktualne – menu powinno być aktualne i odpowiadać aktualnym potrzebom użytkowników.
- Responsywne – menu powinno dostosowywać się do rozmiaru ekranu, aby było czytelne i łatwe do przeglądania na różnych urządzeniach. Bardzo łatwo jest zaprojektować duże menu na desktopy natomiast cholernie trudno na telefony.
- Zawierające odpowiednie słowa kluczowe – menu powinno zawierać odpowiednie słowa kluczowe, które pasują do treści serwisu, co pozwala na lepsze pozycjonowanie w wynikach wyszukiwania. Seowiec zawsze będzie chciał pełne słowa kluczowe natomiast UX skróci je bo nie zmieści tego na urządzeniu mobilnym.
- Dostępne na każdej stronie – menu powinno być dostępne na każdej stronie serwisu, aby użytkownicy mogli łatwo nawigować po serwisie i znaleźć to, czego szukają.
- Uwzględniające potrzeby użytkowników – menu powinno być dostosowane do potrzeb użytkowników, takich jak potrzeby informacyjne, transakcyjne czy edukacyjne.
- Uwzględniające SEO – menu powinno być zaprojektowane tak, aby było przyjazne dla robotów wyszukiwarek, co pozwala na lepsze pozycjonowanie serwisu w wynikach wyszukiwania.
Podsumowując, dobra struktura menu serwisu internetowego to taka, która jest prosta i czytelna, hierarchiczna, intuicyjna, aktualna, responsywna, zawierająca odpowiednie słowa kluczowe, dostępna na każdej stronie, uwzględniająca potrzeby użytkowników i przyjazna dla SEO.
Co seo ukrywa w stopce pozycjonowanej strony www?
Stopka strony internetowej to część strony, która znajduje się na dole każdej strony i zazwyczaj zawiera informacje takie jak linki do polityki prywatności, regulaminu, kontaktu itp. W przypadku pozycjonowania strony, stopka jest często używana do umieszczenia linków zwrotnych do innych podstron, które mogą pomóc w pozycjonowaniu wzmacniając daną podstronę poprzez „moc całego serwisu”.
Niektóre metody pozycjonowania, które mogą zawierać w stopce strony internetowej:
- Linki zwrotne (backlinks) do innych stron, które mogą pomóc w pozycjonowaniu.
- Linki do innych stron w celu rozszerzenia treści serwisu.
- Linki do innych języków wersji serwisu
- Informacje kontaktowe, takie jak adres e-mail lub numer telefonu
- Linki do polityki prywatności oraz regulaminu – zazwyczaj mają nofollow, noindex
Należy pamiętać, że jeśli linki zwrotne w stopce są używane jako metoda pozycjonowania, powinny być one naturalnie umieszczone i powinny być używane tylko do podniesienia jakości treści serwisu oraz dla użytkownika, a nie tylko dla pozycjonowania.
Stopka strony internetowej może być również wykorzystywana do umieszczania linków do tzw. „doorway pages”, czyli stron przejściowych. Są to strony, które są tworzone tylko po to, aby pozycjonować określone frazy kluczowe i przekierowywać użytkowników na inne strony.
Linki do takich stron przejściowych mogą być umieszczane w stopce strony, ponieważ są one zwykle mniej widoczne dla użytkownika niż linki umieszczone w innych częściach strony. Jednak, takie metody pozycjonowania są nieetyczne i mogą być karane przez wyszukiwarki, dlatego ważne jest, aby unikać takich praktyk.
Linki typu doorway pages są już czasem pomijane przez algorytmy wyszukiwarek, ponieważ tego typu strony nie służą do dobrej jakości użytkownikom, a jedynie pozycjonowaniu – wiec Google pomija je w rankowaniu. Co ciekawe pomimo, że Google i inne wyszukiwarki stale walczą z takimi praktykami i mogą nałożyć kary na strony, które je stosują, to jednak one cały czas działają i mają się dobrze.
8. Analiza pliku robots.txt
Analiza pliku robots.txt pozwala na zrozumienie, jakie strony i sekcje serwisu są dostępne dla robotów wyszukiwarek, co ma wpływ na pozycjonowanie serwisu.
- Dlaczego analizujemy plik robots.txt przy pozycjonowaniu – plik robots.txt informuje roboty wyszukiwarek, które strony i sekcje serwisu mają być indeksowane, a które nie. Jeśli plik robots.txt jest skonfigurowany nieprawidłowo, może to prowadzić do problemów z indeksowaniem stron przez roboty wyszukiwarek, co ma negatywny wpływ na pozycjonowanie serwisu.
- Jak powinien wyglądać prawidłowy plik robots.txt – plik robots.txt powinien zawierać instrukcje dla robotów wyszukiwarek dotyczące indeksowania stron serwisu. Instrukcje te mogą obejmować zarówno całkowite zakazy indeksowania, jak i określenie, które sekcje serwisu mają być indeksowane. Plik powinien być poprawnie skonfigurowany, zgodny z protokołem i dostępny pod adresem /robots.txt
Analizując plik robots.txt, należy pamiętać, że niektóre roboty mogą ignorować instrukcje zawarte w pliku robots.txt, dlatego ważne jest, aby upewnić się, że plik jest poprawnie skonfigurowany oraz że nie blokuje on ważnych stron serwisu.
Plik robots.txt powinien być używany tylko do blokowania dostępu do nieistotnych lub prywatnych sekcji serwisu, takich jak archiwalne strony, testowe strony czy panele administracyjne.
Nie powinno się blokować dostępu do plików CSS i JavaScript przez plik robots.txt. Googlebot potrzebuje dostępu do tych plików, aby móc poprawnie zindeksować i wyświetlić stronę, dlatego blokowanie dostępu do tych plików może mieć negatywny wpływ na pozycjonowanie serwisu.
Dodatkowo, blokowanie dostępu do plików CSS i JavaScript może mieć wpływ na poprawne renderowanie strony przez przeglądarki, co może spowodować problemy z dostępnością serwisu dla użytkowników oraz utrudnić proces indeksowania przez roboty wyszukiwarek.
Dlatego ważne jest, aby upewnić się, że plik robots.txt nie blokuje dostępu do plików CSS i JavaScript, aby zapewnić poprawne pozycjonowanie serwisu oraz poprawne działanie dla użytkowników.
O plikach robots.txt można przeczytać tutaj: https://developers.google.com/search/docs/crawling-indexing/robots/intro?hl=pl
9. Analiza budżetu crawl’owania – crawl budget
Crawl budget to ilość stron, jakie wyszukiwarka może przeskanować na Twojej witrynie w danym okresie czasu. Jest to uzależnione od wielu czynników, takich jak popularność witryny, liczba linków zewnętrznych, które prowadzą do witryny oraz ilość treści na niej zawartych.
Aby nie tracić crawl budget, należy przede wszystkim skupić się na optymalizacji struktury witryny, takiej jak:
- Uproszczenie struktury linków wewnętrznych, aby ułatwić robotom wyszukiwarek przeglądanie witryny
- Usuwanie linków nieistniejących i błędnych np. błędy 4xx w linkowaniu wewnętrznym mogą negatywnie wpływać na crawl budget
- Dodanie mapy witryny dla robotów wyszukiwarek
- Zapewnienie unikalnej i wartościowej treści na każdej stronie np. duplikacja treści może powodować pogorszenie indeksacji co ma wypływ na ranking
- Poprawienie szybkości witryny
- Poprawienie meta tagów i adresów URL any unikać ich duplikacji
- Zarządzanie przekierowaniami np. po migracji serwisu na nowe adresy URL wszystkie przekierowania wewnętrzne powinny zostać „wyprostowane”
- Monitorowanie i analizowanie działań robotów wyszukiwarek na witrynie za pomocą narzędzi takich jak Google Search Console
Dwa przydatne linki:
- https://developers.google.com/search/docs/advanced/crawling/large-site- managing-crawl-budget
- https://developers.google.com/search/blog/2017/01/what-crawl-budget- means-for-googlebot
Ważne parametry dla crawl budget
Parametry istotne dla procesu crawl budget to:
- Crawl rate limit to ograniczenie, jakie stawia wyszukiwarka na liczbę stron, jakie mogą być przeskanowane na Twojej witrynie w danym okresie czasu. Jest to ustawione przez wyszukiwarkę, a jego celem jest zapewnienie płynnego działania serwerów wyszukiwarki i uniknięcie przeciążenia.
- Crawl demand to ilość stron, które wyszukiwarka chce przeskanować na Twojej witrynie. Jest to uzależnione od popularności witryny, liczby linków zewnętrznych prowadzących do witryny oraz ilości treści zawartych na niej.
- Crawl health to stan zdrowia witryny, który wpływa na to, jak wyszukiwarka traktuje Twoją witrynę podczas indeksowania. W przypadku zdrowej witryny, wyszukiwarka będzie indeksować ją częściej i szybciej, natomiast w przypadku niezdrowej witryny, indeksowanie może być opóźnione lub wręcz wstrzymane. Crawl health uwzględnia elementy takie jak: szybkość witryny, unikalność treści, poprawność linków wewnętrznych, nagłówki HTTP, mapy witryny, itp.
Aby zwiększyć crawl budget, ważne jest, aby zwiększyć crawl demand poprzez zwiększenie popularności witryny oraz zwiększenie liczby linków zewnętrznych prowadzących do witryny. Można to osiągnąć poprzez:
- Publikowanie unikalnej i wartościowej treści, która będzie chętnie udostępniana i linkowana przez inne witryny.
- Zwiększenie zasięgu witryny poprzez działania SEO i reklamy.
- Zwiększenie liczby linków wewnętrznych na witrynie, co pozwala na łatwiejsze przeglądanie treści przez roboty wyszukiwarek.
Aby zwiększyć crawl rate limit, ważne jest, aby poprawić crawl health witryny poprzez:
- Optymalizację szybkości witryny, aby roboty wyszukiwarek mogły szybciej przeskanować strony.
- Usuwanie błędów i problemów z linkami wewnętrznymi oraz poprawienie struktury linków.
- Dodanie mapy witryny dla robotów wyszukiwarek.
- Usuwanie linków nieistniejących i generujących błędnych
- Zwiększanie unikalności i wartości treści na witrynie.
Podsumowując, aby zwiększyć crawl budget, ważne jest zwiększenie crawl demand poprzez zwiększenie popularności witryny oraz zwiększenie liczby linków zewnętrznych prowadzących do witryny oraz zwiększenie crawl rate limit poprzez poprawienie crawl health witryny.
10. Wersja HTTPS versus HTTP oraz mixed content
HTTPS (Hypertext Transfer Protocol Secure) jest wersją protokołu HTTP, która zapewnia bezpieczne połączenie między przeglądarką a serwerem. Jest to ważne dla SEO, ponieważ wyszukiwarki, takie jak Google, preferują witryny korzystające z HTTPS, i są one uważane za bardziej bezpieczne dla użytkowników. Czy korzystanie z HTTPS może również przynieść nieco lepsze pozycje w wynikach wyszukiwania to można by polemizować aczkolwiek Google stoi na stanowisku, że SSL jakieś tam znaczenie dla SEO ma – jednak nikt tego testami nie potwierdził
Mixed content to sytuacja, w której witryna ładuje zarówno zasoby bezpieczne (HTTPS), jak i niezabezpieczone (HTTP) na tej samej stronie. Jest to problem, ponieważ przeglądarka nie może zagwarantować bezpieczeństwa dla użytkownika, jeśli na tej samej stronie ładowane są zarówno bezpieczne, jak i niezabezpieczone zasoby – najczęściej można to spotkać np. w obrazkach na stronie.
Witryny z mixed content mogą mieć problemy z pozycjonowaniem oraz mają ryzyko, że ich użytkownicy mogą widzieć ostrzeżenia o niebezpieczeństwie, co może zniechęcić ich do dalszej nawigacji po witrynie. Dlatego ważne jest, aby zapewnić, że wszystkie zasoby ładowane na stronie są bezpieczne i pochodzą z HTTPS.
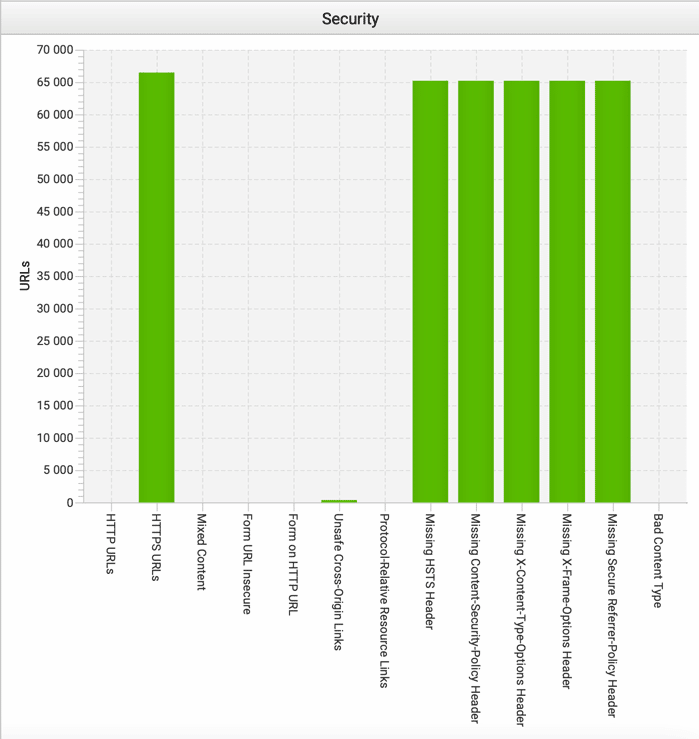
Jak zabezpieczyć się przed mixed content?
Aby zabezpieczyć się przed zjawiskiem mixed content na stronie www, należy podjąć następujące kroki:
- Przeprowadzić audyt zasobów: Przejrzyj wszystkie zasoby ładowane na stronie, takie jak obrazy, skrypty i filmy, i upewnij się, że są one ładowane z protokołem HTTPS. Możesz skorzystać z narzędzi do analizy treści, takich jak Screaming Frog, Sitebulb czy darmowy XENU lub Macroscope, aby automatycznie wykryć mixed content na stronie.
- Korzystać z absolutnych adresów URL: Zamiast korzystać z relatywnych adresów URL, takich jak „img/logo.png”, używaj absolutnych adresów URL, takich jak „https://example.com/img/logo.png„, co pozwoli uniknąć problemów związanych z mixed content.
- Sprawdzanie skryptów: Jeśli korzystasz z zewnętrznych skryptów lub bibliotek, upewnij się, że są one ładowane z protokołem HTTPS.
- Używać tagu rel=”preload” : Tag rel=”preload” pozwala na wstępne ładowanie zasobów, co pozwala na uniknięcie problemów związanych z mixed content.
- Monitorowanie i testowanie: Regularnie monitoruj swoją witrynę pod kątem mixed content i testuj ją z różnymi przeglądarkami i urządzeniami, aby upewnić się, że nie ma problemów związanych z mixed content.
- Aktualizacja kodu: jeśli masz już mixed content na stronie, należy dokonać aktualizacji kodu, zmienić wszystkie adresy URL na https, a także sprawdzić wszystkie skrypty, które są używane na stronie.
- Używanie pluginów i narzędzi: Istnieją różne rozszerzenia i narzędzia, które mogą pomóc w automatycznym rozwiązaniu problemów związanych z mixed content na stronie. Przykłady takich rozszerzeń to „Mixed Content Fixer” dla WordPress lub „Mixed Content Blocker” dla Chrome.
- Weryfikacja konfiguracji serwera: Upewnij się, że serwer jest skonfigurowany poprawnie, aby przekierowywał wszystkie żądania HTTP na HTTPS.
- Wsparcie dla użytkowników: Jeśli twoja witryna ma już problemy z mixed content, ważne jest, aby poinformować o tym swoich użytkowników i pomóc im w rozwiązaniu problemu.
- Regularne aktualizacje: Regularnie aktualizuj swoją witrynę i rozwiązuj problemy związane z mixed content tak szybko, jak to możliwe. Pamiętaj, że mixed content jest problemem ciągłym i wymaga stałego monitorowania i rozwiązywania problemów.
- Przekierowania 301: Stosuj przekierowania z wersji nonSSL (bez certyfikatu) na wersję z certyfikatem aby uniknąć mixed content.
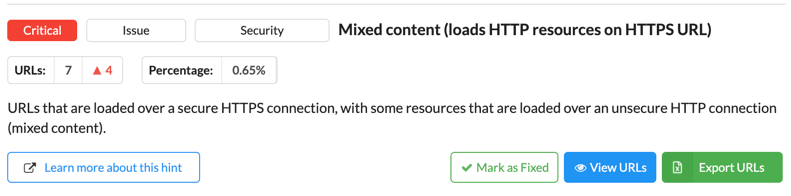
Warto pamiętać, że choć przejście na protokół HTTPS jest krokiem w kierunku zwiększenia bezpieczeństwa i lepszego pozycjonowania witryny, to samo przejście nie gwarantuje sukcesu. Wymaga to również dbania o zasoby ładowane na stronie, aby upewnić się, że wszystko jest ładowane z protokołem HTTPS, co pozwoli uniknąć problemów związanych z mixed content.
11. Analiza duplikacji treści wewnętrznej i zewnętrznej
Aby analizować duplikację treści serwisu, można użyć narzędzi takich jak Copyscape, Siteliner lub Google Search Console. Te narzędzia pozwalają na wykrycie duplikacji treści wewnętrznej (na różnych podstronach serwisu) oraz zewnętrznej (na innych stronach internetowych).
Duplikacja treści wewnętrzna może negatywnie wpływać na pozycję serwisu w wynikach wyszukiwania, ponieważ wyszukiwarki mogą traktować takie strony jako mniej wartościowe.
Duplikacja treści zewnętrznej może natomiast skutkować obniżeniem pozycji serwisu w wynikach organicznych. Podkreślam – MOŻE – ale nie musi. O tym dalej.
Aby uniknąć duplikacji treści, należy przede wszystkim stworzyć unikalną i oryginalną treść dla każdej podstrony serwisu. Warto też pamiętać o tym, aby nie kopiować treści z innych stron internetowych, nawet jeśli są one na tej samej tematyce. W przypadku, gdy kopiowanie treści jest nieuniknione, należy zawsze podawać źródło i stosować odpowiednie oznaczenia, takie jak cytaty.
Innym sposobem na uniknięcie duplikacji treści jest stosowanie przeciwdziałania duplikacji na poziomie technicznym. Można to osiągnąć poprzez ustawienie odpowiednich nagłówków HTTP, takich jak „Rel=Canonical” lub „X-Robots-Tag”, które pozwalają wyszukiwarkom wskazać, która strona jest oryginalna.
Podsumowując, duplikacja treści jest problemem, który może negatywnie wpływać na pozycję serwisu w wynikach wyszukiwania. Dlatego ważne jest, aby regularnie sprawdzać serwis pod kątem duplikacji treści i podjąć odpowiednie działania, aby ją usunąć.
Przyczyny powstawania duplikacji treści wewnątrz serwisu
Poniżej przedstawiamy listę przykładowych przyczyn duplikacji treści:
- problemy z protokołem odpowiedzi,
- publikacja i indeksacja niegotowych stron np. wersji testowej serwisu
- źle wdrożone wersje językowe strony,
- powielona treść na stronach kategorii np. przy stronicowaniu opis kategorii znajduje się na każdej podstronie
- korzystanie z opisów produktów pochodzących od producenta ale niejednokrotnie tego nie da się uniknąć
- błędy skryptu,
- duplikacja spowodowana filtracją i sortowaniem.
Jak sobie poradzić z taką treści? Na przykład poprzez:
- usunięcie lub ograniczenie powielanej treści,
- zapoznanie się z systemem CMS i rozwiązanie problemów ze skryptem,
- zabezpieczenie niegotowych treści przed indeksacją,
- zastosowanie parametrów,
- użycie domen najwyższego poziomu,
- zapewnienie możliwości indeksacji tylko jednej wersji strony,
- zastosowanie przekierowań 301,
- zastosowanie tagu kanonicznego,
- scalenie podstron z róznymi wariantami do jednej podstrony
Więcej na temat duplikacji treści po stronie Google znajdziemy w tym poradniku: https://developers.google.com/search/docs/advanced/guidelines/duplicate-content
12. Indeksacja i dostępność podstron dla Google
Indeksacja serwisu w Google polega na tym, że Googlebot (robot Google) analizuje i przeszukuje strony internetowe, aby zrozumieć ich treść i uwzględnić je w wynikach wyszukiwania. Proces indeksacji jest kluczowy dla pozycji serwisu w wynikach wyszukiwania, ponieważ tylko zindeksowane strony mogą być wyświetlane w wynikach wyszukiwania.
Aby ułatwić indeksację serwisu w Google, należy przestrzegać następujących wytycznych:
- Stworzenie pliku robots.txt: Plik robots.txt pozwala na kontrolowanie, które strony serwisu mają być indeksowane przez roboty wyszukiwarek.
- Tworzenie mapy strony: Mapa strony pozwala na prezentowanie wszystkich podstron serwisu robotom wyszukiwarek, co ułatwia ich indeksację.
- Tworzenie linków wewnętrznych: Linki wewnętrzne pozwalają robotom wyszukiwarek na łatwe przemieszczanie się po serwisie i indeksowanie jego podstron.
- Unikanie duplikacji treści: Duplikacja treści może negatywnie wpływać na indeksację serwisu w Google, dlatego ważne jest, aby unikać jej powstawania.
- Tworzenie treści unikalnej: Google preferuje treści unikalne, dlatego ważne jest, aby stworzyć unikalną i oryginalną treść dla każdej podstrony serwisu.
- Użycie odpowiednich nagłówków: Użycie nagłówków, takich jak H1, H2 itp. pozwala na lepsze rozumienie treści przez roboty wyszukiwarek.
- Monitoring serwisu: Regularnie monitoruj swój serwis w Google Search Console, aby upewnić się, że wszystkie podstrony są prawidłowo indeksowane.
- Tworzenie linków zewnętrznych: Linki zewnętrzne z innych stron internetowych do Twojego serwisu mogą pomóc w jego indeksacji.
Te wytyczne pozwolą na ułatwienie indeksacji serwisu w Google, jednakże nie gwarantują, że wszystkie podstrony zostaną zindeksowane. Proces indeksacji może być długi i zależy od wielu czynników, takich jak jakość treści, liczba linków wewnętrznych i zewnętrznych oraz popularność serwisu.
Ważne jest również regularne sprawdzanie, czy wszystkie podstrony serwisu są prawidłowo indeksowane w Google. Można to zrobić przy pomocy narzędzia Google Search Console, które pozwala na sprawdzanie, które podstrony zostały zindeksowane oraz udostępnia informacje o błędach indeksowania.
Z czego składa sie proces crawlowania i indeksacji serwisu w google
Proces crawlowania i indeksacji serwisu w Google składa się z kilku kroków:
- Crawl (pobieranie): Googlebot (robot Google) pobiera strony internetowe za pomocą linków zawartych na nich, przeszukując również inne zasoby, takie jak mapy stron czy pliki robots.txt, które pozwalają na kontrolowanie, które strony mają być przeszukane.
- Analiza: Googlebot analizuje pobrany kod HTML oraz inne zasoby, takie jak obrazy i filmy, aby zrozumieć treść strony oraz jej strukturę.
- Indeksacja: Google indeksuje pobraną treść, tworząc wirtualny indeks, który pozwala na łatwe i szybkie przeszukiwanie treści.
- Rangowanie: Google analizuje różne czynniki, takie jak jakość treści, linki wewnętrzne i zewnętrzne oraz popularność serwisu, aby określić jego pozycję w wynikach wyszukiwania.
- Wyświetlanie: Gdy użytkownik wprowadza zapytanie, Google przeszukuje swój indeks treści i wybiera najlepsze pasujące strony, które są wyświetlane w wynikach wyszukiwania.
- Aktualizacja: Proces indeksacji i crawlowania jest ciągły, co oznacza, że Googlebot będzie regularnie odwiedzać strony, aby sprawdzić czy zawartość się zmieniła i dostosować indeks do aktualnych zmian.
Podsumowując, proces crawlowania i indeksacji serwisu w Google polega na pobraniu i analizie treści serwisu, tworzeniu indeksu treści, określeniu pozycji serwisu w wynikach wyszukiwania oraz wyświetlaniu wyników wyszukiwania dla użytkowników.
Google może pobrać stronę, wykona crawl ale nie musi jej zaindeksować – strona stoi wtedy w kolejce do indeksowania. Stąd pojawiające się informacje w GSC tego typu (źródło: https://support.google.com/webmasters/answer/7440203?hl=pl):
Strona zeskanowana, ale jeszcze niezindeksowana
Strona została zeskanowana, ale nie została jeszcze zindeksowana przez Google. Strona może zostać zindeksowana w przyszłości. Nie ma potrzeby ponownego przesyłania tego adresu URL do zeskanowania.
Strona wykryta – obecnie niezindeksowana
Strona została już znaleziona, ale nie została jeszcze zindeksowana przez Google. Najczęstszą przyczyną tego stanu jest to, że próba zindeksowania danego adresu URL przez Google mogła przeciążyć stronę i indeksowanie zostało zaplanowane na później. Właśnie dlatego data ostatniego indeksowania w raporcie jest pusta.
Więcej na temat indeksowania serwisu przeczytasz tutaj: https://developers.google.com/search/docs/crawling-indexing
13. Analiza przekierowań 3xx
Przekierowanie 301 to metoda przekierowywania ruchu z jednej strony internetowej na inną. Jest to najczęściej stosowany typ przekierowania, ponieważ informuje wyszukiwarki, że przekierowanie jest trwałe i że zawartość została przeniesiona na nowy adres URL.
Przekierowanie 301 jest stosowane w sytuacjach, gdy:
- strona została przeniesiona na nowy adres URL
- strona została usunięta lub zmodyfikowana
- strona została przeniesiona z http na https
Działanie przekierowania 301 polega na tym, że gdy użytkownik lub robot wyszukiwarki odwiedzi stary adres URL, zostanie automatycznie przekierowany na nowy adres URL. To przekierowanie zapewnia, że ruch zostanie przeniesiony na nowy adres, a wyszukiwarki będą wiedzieć, że zawartość została przeniesiona i nie należy już indeksować starego adresu URL.
W pozycjonowaniu, przekierowanie 301 jest ważne, ponieważ pozwala na przeniesienie „mocy” linków z poprzedniej strony na nową, co pozytywnie wpływa na pozycję w wyszukiwarce. Przed implementacją przekierowania 301 należy jednak upewnić się, że nowy adres URL jest odpowiednio przygotowany i optymalizowany pod kątem pozycjonowania.
Łańcuchy przekierowań
Łańcuchy przekierowań 301 to sytuacja, w której ruch jest przekierowywany z jednego adresu URL na kolejny, a następnie na kolejny itd.
Jeśli łańcuch przekierowań jest zbyt długi lub zawiera błędy, może to negatywnie wpływać na pozycję strony w wyszukiwarce oraz na doświadczenie użytkownika.
Aby radzić sobie z łańcuchami przekierowań 301, należy:
- Upewnić się, że przekierowania są konfigurowane poprawnie i nie zawierają błędów
- Unikać tworzenia zbyt długich łańcuchów przekierowań – im krótszy łańcuch przekierowań, tym lepiej czyli doprowadzamy do sytuacji, w której mamy tylko jeden przeskok w przekierowywanych adresach URL
- Monitorować ruch na stronie i wykrywać i usuwać łańcuchy przekierowań, które pojawiają się bez powodu. Można to znaleźć w Search Console w zakładce „przekierowania” a następnie zweryfikować to narzędziem np. Screaming Frog czy httpstatus.io
- Jeśli to możliwe, unikaj przekierowywania ruchu na strony trzecie
- Jeśli jest to konieczne, przenieść linki z poprzedniego adresu URL na nowy za pomocą linków zwrotnych. Czyli mając link na stronie www do podstrony A kontaktujesz się z właścicielem strony i prosisz o zmianę linka do podstrony B.
Pamiętaj, że najlepszym rozwiązaniem jest unikanie tworzenia łańcuchów przekierowań, jeśli jest to możliwe, i stosowanie przekierowań 301 tylko wtedy, gdy jest to absolutnie konieczne.
Łańcuchy przekierowań negatywnie wpływają na crawl budget wiec tym bardziej zasadne jest ich usunięcie.
Przekierowania 301 w linkowaniu wewnętrznym
Przekierowanie 301 w linkowaniu wewnętrznym oznacza przekierowywanie użytkowników z jednej podstrony na inną za pomocą linków wewnątrz serwisu. To nie jest idealne rozwiązanie, ponieważ przekierowanie 301 powinno być stosowane tylko w przypadku przenoszenia zawartości na nowy adres URL, a nie do przemieszczania ruchu wewnątrz serwisu.
Unikanie przekierowań w linkowaniu wewnętrznym jest ważne, ponieważ:
- Przekierowanie 301 powoduje utratę mocy linków wewnętrznych, co negatywnie wpływa na pozycję strony w wyszukiwarce
- Przekierowanie 301 może spowodować, że roboty wyszukiwarki będą mniej często odwiedzać dane podstrony, co może negatywnie wpłynąć na indeksowanie i pozycję strony
- Przekierowanie 301 może negatywnie wpłynąć na doświadczenie użytkownika, ponieważ przekierowanie do innej podstrony może być nieoczekiwane lub niezrozumiałe
Zamiast stosowania przekierowań 301 w linkowaniu wewnętrznym, lepiej jest używać linków bezpośrednich, które pozwalają użytkownikom i robotom wyszukiwarki poruszać się po serwisie bez przeszkód.
Więcej na temat przekierowań znajdziesz tutaj: https://developers.google.com/search/docs/advanced/crawling/301-redirects?hl=pl
14. Linkowanie wewnętrzne ważnym aspektem analizy w audycie seo
Linkowanie wewnętrzne ma za zadanie wskazać połączenia pomiędzy stronami wewnątrz serwisu. Linkowanie wewnętrzne pozwala na łatwe przemieszczanie się po stronie i ułatwia użytkownikom i robotom wyszukiwarek odnalezienie ważnych treści na stronie. Przykłady linkowania wewnętrznego to: linki w menu nawigacyjnym, linki w treści artykułów, linki w stopce strony.
Z punktu widzenia SEO dobrze zrobiony PageRank Sculpting pozwala tylko samym linkowaniem wewnętrznym wykonać pozycjonowanie podstron.
Linkowanie wewnętrzne jest ważnym elementem architektury informacji strony internetowej, ponieważ pozwala na lepsze indeksowanie strony przez roboty wyszukiwarek. Dzięki linkowaniu wewnętrznemu roboty wyszukiwarek mogą łatwiej znaleźć i zindeksować ważne treści na stronie, co przekłada się na lepszą widoczność strony w wynikach wyszukiwania.
Elementy, które należy zawrzeć w stronie w celu poprawy linkowania wewnętrznego i indeksacji serwisu:
- odpowiednie zaplanowanie i wykonanie linkowania w menu głównym,
- dodatkowe menu boczne dla stron kategorii,
- linki ze stopki serwisu,
- wdrożenie na stronie menu okruszkowego,
- linkowanie z warstwy tekstowej strony,
- linkowanie z kafelków typu: powiązane produkty, podobne artykuły,
- mapa HTML serwisu (opcjonalnie).
Linki wewnętrzne jako element indeksacji serwisu
Linkowanie wewnętrzne jest ważnym elementem indeksowania podstron w serwisie. Linkowanie wewnętrzne pozwala robotom wyszukiwarek na łatwe przeszukiwanie i zindeksowanie treści znajdujących się na różnych podstronach serwisu.
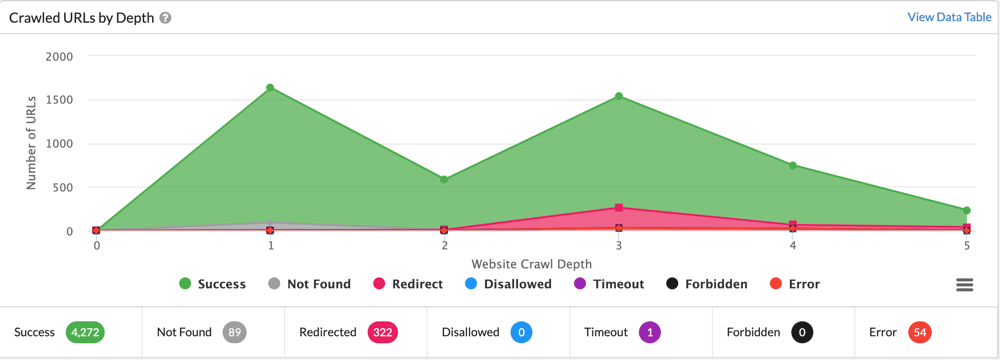
Roboty wyszukiwarek wykorzystują linki wewnętrzne, aby przejść z jednej podstrony na drugą i zindeksować treści znajdujące się na nich. Dzięki temu, strony znajdujące się wewnątrz serwisu są lepiej widoczne w wynikach wyszukiwania, co przekłada się na lepszą widoczność całego serwisu.
Elementy, które wpływają na lepsze indeksowanie to chociażby:
- stronicowanie
- galerie np. obrazków
- wpisy podobne
- produkty podobne lub z tej samej serii itd.
Orphaned pages – treści osierocone
Orphaned pages (ang. „osierocone strony”) to strony, które nie są połączone z żadnymi innymi stronami na danej witrynie. Tzn. że nie są dostępne dla użytkowników i dla robotów wyszukiwarek przez żadne linki wewnętrzne lub po prostu prowadzi do nich tylko jeden link wewnętrzny.
W pozycjonowaniu, orphaned pages mogą mieć negatywny wpływ na indeksację, ponieważ roboty wyszukiwarek mogą mieć trudności z odnalezieniem i zindeksowaniem tych stron. Strony te nie są również dostępne dla użytkowników, co oznacza, że nie przynoszą żadnej wartości dla witryny.
Aby uniknąć tworzenia orphaned pages, ważne jest, aby wszystkie strony na witrynie były połączone z innymi stronami poprzez linkowanie wewnętrzne. Dzięki temu roboty wyszukiwarek mogą łatwiej przeszukiwać witrynę i zindeksować treści znajdujące się na różnych podstronach.
Aby zminimalizować liczbę orphaned pages, warto regularnie sprawdzać swoją witrynę pod kątem brakujących linków wewnętrznych i uzupełniać je tam, gdzie to konieczne. Można też skorzystać z narzędzi, które pozwolą na automatyczne wykrycie opuszczonych stron. W narzędziach takie podstrony są pokazywane jako te, do których prowadzi 10 lub więcej przeklików (czyli mają daleką ścieżkę dotarcia do nich).
Z reguły osierocone treści mogą powstawać poprzez niewłaściwie wykonane stronicowanie bo produkt lub usługa znajduje się na ostatniej stronie stronicowania.
Jak dobrze wykonać linkowanie wewnętrzne?
Aby dobrze wykonać linkowanie wewnętrzne, należy zwrócić uwagę na kilka ważnych aspektów:
- Struktura nawigacji: linkowanie wewnętrzne powinno być zintegrowane z menu nawigacyjnym witryny, aby użytkownicy i roboty wyszukiwarek mogły łatwo przemieszczać się po stronie. Ważne jest aby do każdej podstrony dało się dotrzeć w jak najmniejszej liczbie kliknięć. Kiedyś zwracało się uwagę aby już w 3-cim przekliku dotrzeć do podstrony. Dzisiaj po prostu architektura ma być przejrzysta a scenariusz i ścieżka możliwie najkrótsza.
- Hierarchia treści: linkowanie wewnętrzne powinno odzwierciedlać hierarchię treści witryny, aby roboty wyszukiwarek mogły łatwiej zrozumieć strukturę serwisu.
- Linki wewnętrzne w treści: linkowanie wewnętrzne powinno być również umieszczone w treści witryny, aby użytkownicy mogli łatwo przejść do powiązanych treści bez konieczności przeszukiwania całej strony.
- Opisy linków: linki wewnętrzne powinny mieć opisy, które precyzyjnie opisują, do czego prowadzą.
- Unikanie osieroconych podstron: ważne jest, aby unikać tworzenia osieroconych stron, czyli takich, które nie są połączone z żadnymi innymi stronami na danej witrynie.
- Monitoring: ważne jest regularne monitorowanie linków wewnętrznych i uzupełnianie ich tam, gdzie to konieczne, aby uniknąć uszkodzeń czy brakujących linków. I tutaj ważnymi aspektami są: unikanie zbędnych przekierowań 301, nadzór i analiza powstających błędów 404 i ich bieżące usuwanie.
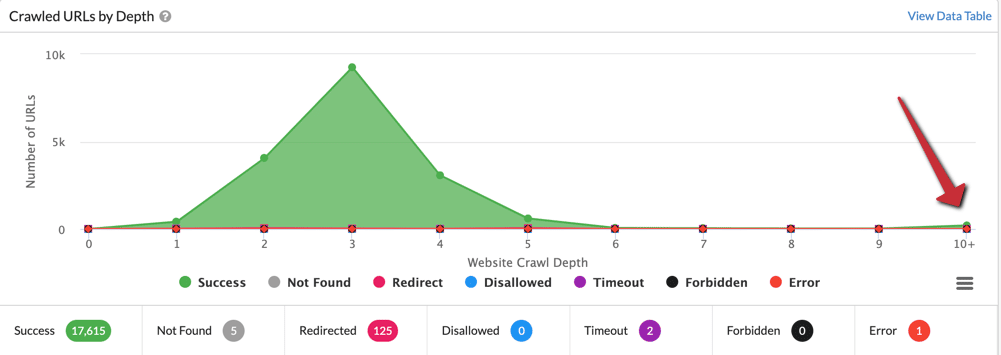
Dobrze wykonane linkowanie wewnętrzne pozwala na lepsze zrozumienie struktury serwisu przez roboty wyszukiwarek, co przekłada się na lepsze indeksowanie podstron oraz ułatwia użytkownikom przemieszczanie się po serwisie.
Ciekawe opracowania nt. linkowania wewnętrznego:
- https://audisto.com/guides/pagination
- https://www.semrush.com/blog/seo-friendly-pagination-ecommerce/
- https://ahrefs.com/blog/rel-prev-next-pagination/
- https://www.portent.com/blog/seo/pagination-tunnels-experiment-click-depth.htm
15. Mapy Strony XML oraz HTML
Aby utworzyć mapę strony XML, musisz stworzyć plik zawierający wpisy dotyczące stron twojej witryny, które chcesz, aby wyszukiwarki widziały. Format tego pliku powinien być spełniający wymogi Google i innych wyszukiwarek. Następnie należy umieścić plik mapy strony na swoim serwerze i dodać adres URL do mapy strony w panelu Google Search Console.
Aby zarządzać mapami strony XML, musisz regularnie sprawdzać mapę strony w Google Search Console, aby upewnić się, że wszystkie linki są aktualne i poprawne, oraz uaktualniać mapę, jeśli zmieni się struktura lub zawartość Twojej witryny – ale to ostatnie powinien wykonywać skrypt CMS czy sklepu internetowego, którym zarządzasz.
Aby przygotować mapę strony XML, musisz spełnić następujące kroki:
- Stwórz plik tekstowy z rozszerzeniem .xml. Możesz to zrobić za pomocą edytora tekstu lub specjalnego narzędzia do tworzenia map stron XML.
- Zdefiniuj nagłówek pliku. Powinien on zawierać informację o tym, że jest to mapa strony XML oraz adres URL Twojej witryny.
- Dodaj wpisy dla każdej strony witryny, którą chcesz, aby wyszukiwarki widziały. Każdy wpis powinien zawierać adres URL strony oraz datę ostatniej modyfikacji.
- Użyj tagów <url> i <lastmod> dla każdego wpisu. Przykład:
<url>
<loc>https://example.com/page1</loc>
<lastmod>2022-01-01</lastmod>
</url>
- Zakończ plik znacznikiem zamykającym, takim jak „</urlset>”.
- Sprawdź czy mapa jest poprawnie sformatowana za pomocą narzędzi do walidacji mapy strony xml.
- Umieść plik mapy strony na swoim serwerze i dodać adres URL do mapy strony w panelu Google Search Console.
Mapa powinna uaktualniać się automatycznie po zmianach dokonanych na stronie www.
W mapie strony XML dodajemy adresy URL działające zwracające kod „http 200 ok”. Innych adresów nie należy umieszczać z uwagi na crawl budget.
Mapa strony w HTML
Ten serwis w stopce ma stronę w HTML-u – obejrzyj 😉
Mapa strony wykonana w HTML jest tak samo ważna dla pozycjonowania jak mapa strony XML, która jest przeznaczona specjalnie dla wyszukiwarek. Mapa strony w HTML jest przeznaczona dla użytkowników, którzy chcą szybko znaleźć informacje na stronie, ale również dla wyszukiwarek.
Mapa strony w HTML jest jednak ważna z punktu widzenia linkowania wewnętrznego. Dzięki temu, że zawiera ona linki do różnych stron na Twojej witrynie, pomaga wyszukiwarkom zrozumieć strukturę Twojej witryny i indeksować ją lepiej.
Mapa strony w HTML może także zapobiegać powstawaniu osieroconych treści, czyli treści, które nie są połączone z innymi stronami na Twojej witrynie. Dzięki temu, że mapa strony zawiera linki do różnych stron, wyszukiwarki mogą łatwiej odnaleźć i indeksować te treści.
Jak dodać mapę strony xml w google search console?
Aby dodać mapę strony XML do Google Search Console, musisz wykonać następujące kroki:
- Zaloguj się do swojego konta w Google Search Console.
- Wybierz witrynę, dla której chcesz dodać mapę strony XML.
- Kliknij na zakładkę „Indeksowanie” i wybierz „Mapy witryn”.
- Na ekranie w miejscu „Dodaj nową mapę witryny” wpisz adres URL swojej mapy strony XML.
- Kliknij przycisk „Prześlij”.
- Google Search Console przeanalizuje Twój plik mapy strony i wyświetli informację o jego statusie. Jeśli wszystko jest w porządku, plik zostanie zatwierdzony i indeksowany przez Google.
- Pamiętaj, żeby regularnie sprawdzać status mapy strony w Google Search Console i uaktualniać ją, jeśli zmieni się struktura lub zawartość Twojej witryny.
UWAGA: Jeśli nie posiadasz mapy strony XML, należy ją najpierw przygotować i umieścić na serwerze, aby móc ją dodać do Google Search Console
Ważne: jeśli masz problem z pobraniem mapy w GSC możesz ją spingować za pomocą adresu w Google.
Więcej na temat mapy strony pod adresem: https://developers.google.com/search/docs/crawling-indexing/sitemaps/build-sitemap?hl=pl
16. Kody odpowiedzi serwisu
To ważne aby zweryfikować jakie odpowiedzi otrzymuje Googlebot od serwisu. Każda konfiguracja serwera, skryptu jest różna i może powodować mniejsze lub większe problemy.
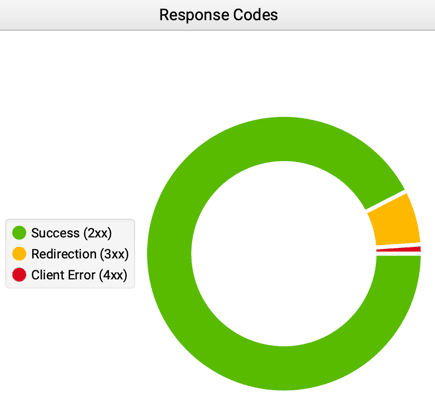
Kody 300 to kody odpowiedzi dla żądań przekierowania. Oznaczają one, że zasób, o który klient wystąpił, znajduje się w innym miejscu i że klient powinien przesłać żądanie do nowego adresu URL. Przykładami kodów tego typu są: 301 (przekierowanie trwałe), 302 (przekierowanie tymczasowe) i 307 (przekierowanie tymczasowe zachowanie metody).
Kody 400 to kody odpowiedzi dla błędów klienta. Oznaczają one, że żądanie było nieprawidłowe lub niepoprawne, i że klient powinien poprawić błąd i ponowić żądanie. Przykładami kodów tego typu są: 400 (nieprawidłowe żądanie), 401 (brak autoryzacji), 403 (brak dostępu) i 404 (nie znaleziono).
Kody 500 to kody odpowiedzi dla błędów serwera. Oznaczają one, że serwer napotkał problem podczas próby obsłużenia żądania i nie jest w stanie zrealizować żądania. Przykładami kodów tego typu są: 500 (błąd serwera), 501 (nie zaimplementowano) and 503 (usługa niedostępna).
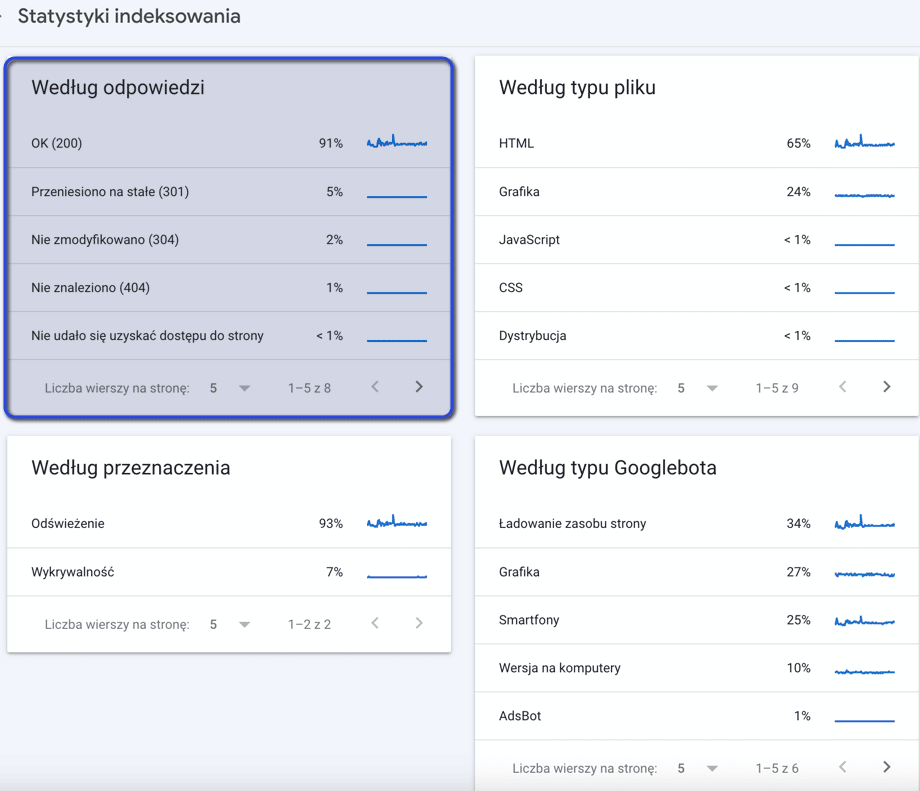
Gdzie sprawdzić kody odpowiedzi w Search Console
W Google Search Console kody odpowiedzi znajdziemy w zakładce Ustawienia -> Statystyki indeksowania:
Poniżej przykładowy wykres z GSC dla błędów 404:
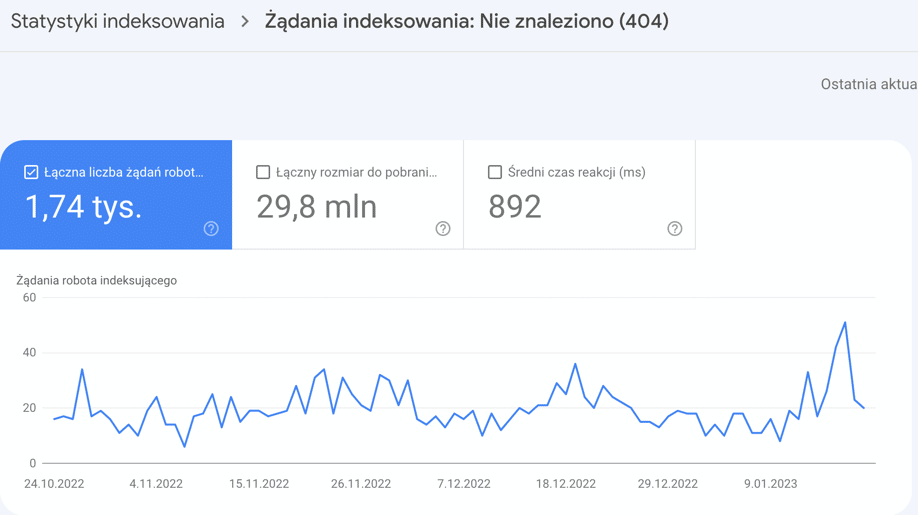
Oznaczenia kodów odpowiedzi są podobne jak w odpowiedzi wyżej
- 2xx to kody odpowiedzi dla żądań zakończonych powodzeniem,
- 3xx to kody odpowiedzi dla żądań przekierowania,
- 4xx to kody odpowiedzi dla błędów klienta,
- 5xx to kody odpowiedzi dla błędów serwera.
Jeśli webmaster widzi dużą liczbę kodów odpowiedzi 4xx lub 5xx, oznacza to, że mogą występować problemy z dostępnością lub funkcjonalnością strony. Webmaster powinien zbadać przyczyny tych problemów i podjąć odpowiednie działania, aby je naprawić.
Audyt SEO powinien zawierać analizę tych kodów oraz rekomendacje związane z nimi przykładowo:
- analiza błędów 404 może wskazywać, że należy wykonać przekierowania 301 aby uniknąć straty mocy SEO dla linków zewnętrznych, które takie błędy generują. Może też wskazywać na częste usuwanie podstron (np. produktów w sklepie) i należy odpowiednio reagować
- analiza przekierowań 301 może doprowadzić do utraty crawl budgetu ponieważ jest ich po prostu za dużo. W tym momencie nalezy zweryfikować linkowanie wewnętrzne i przekierowania usunąć
- nagromadzenie błędów 5xx (dowolnych) to już praca zarówno dla programistów (problemy ze skryptem) jak również osób odpowiedzialnych za hosting (może być za słaby i mało wydajny)
Wpis nie został jeszcze skończony i będzie rozwijany. Planowane ukończenie to 31 stycznia 2023. Jednocześnie wpis ten został opublikowany i jest testowany pod kątem indeksowania oraz rankowania i tego jak zareaguje Google na nieskończony tekst i jego sukcesywne rozbudowywanie i uzupełnianie.
Jeśli chcesz o coś zapytać w sprawie audytów SEO dzwoń na 606 628 628.
Pytania dotyczące tematu co zawiera audyt seo?
Jakie elementy składają się na audyt SEO?
Audyt SEO składa się z analizy technicznej, analizy treści, analizy linków oraz analizy konkurencji.
W jakim celu wykonywany jest audyt SEO?
Audyt SEO jest wykonywany w celu identyfikacji problemów związanych z pozycjonowaniem strony internetowej oraz określenia działań, które pomogą poprawić widoczność serwisu w wynikach wyszukiwania.
Jakie działania mogą być zalecane po wykonaniu audytu SEO?
Po wykonaniu audytu SEO zalecane działania mogą obejmować m.in. optymalizację kodu strony, poprawę struktury nagłówków, dodanie alt-tagów, tworzenie wartościowej treści oraz pozyskiwanie linków.
Jak często należy wykonywać audyt SEO?
Audyt SEO powinien być wykonywany regularnie, co najmniej raz w roku, aby utrzymać wysoką pozycję w wynikach wyszukiwania i dostosować strategię do zmieniających się algorytmów wyszukiwarek.



